Video
Die häufigsten, im Internet anzutreffenden Videoformate sind H.261, H.263, MPEG-1 und MPEG-2. Bei diesen vier Formaten handelt es sich um hybride blockorientierte Verfahren, die räumliche (intra-frame) und zeitliche (inter-frame) verlustbehaftete Kompression einsetzen.
Farbraum
Bei der Videocodierung in den obigen Formaten wird nicht der bekannte RGB-Farbraum, sondern der YCrCb-Farbraum (auch YUV genannt) genutzt, der die drei Farbwerte (Rot, Grün und Blau) als Helligkeit (Luminanz) und zwei Farbdifferenzen (Chrominanz) darstellt. Eine Umwandlung der Räume kann nach den folgenden Formeln erfolgen:
Y = 0.299R + 0.587G + 0.114B
Cr = R - Y
Cb = B - Y
Untersuchungen haben ergeben, dass die Helligkeitswerte für das menschliche Auge die meisten Informationen tragen. Änderungen in der Helligkeit werden also stärker wahrgenommen, als Änderungen in der Farbe. Diese Tatsache kann bereits zur Kompression genutzt werden, indem z.B. nur die Hälfte der Chrominanzinformationen gespeichert werden, ohne dass ein spürbarer Qualitätsverlust auftritt. Diese Technik wird auch bei den hier betrachteten Videocodierungen eingesetzt und als Verhältnis bzgl. der einzelnen Komponenten angegeben (z.B. 4:2:2).
Grundsätzliches Codierverfahren bei H.261, H.263, MPEG-1 und MPEG-2
Die Erzeugung von Videodaten in diesen Formaten beruht im Wesentlichen auf gleiche oder sehr ähnliche Verfahren, die im Folgenden kurz dargestellt werden. Da die einzelnen Standards nicht das eigentliche Codierverfahren, sondern nur eine Beschreibung des Codes enthalten, ist es kaum möglich, die Funktionsweise eines allgemeinen Codierers zu beschreiben. Vielmehr können nur die grundsätzlichen Mechanismen erläutert werden, die in einem Codierer zum Einsatz kommen.
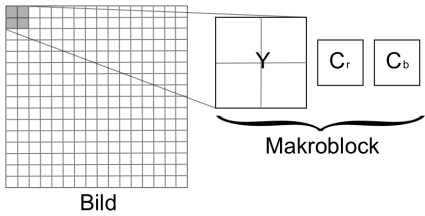
Makroblöcke
Die einzelnen Bilder (auch Frames genannt) werden in 8 x 8 Pixel große Blöcke aufgeteilt, von denen jeweils vier benachbarte Blöcke zu einem Makroblock zusammengefasst werden. Die Blöcke werden im YCrCb-Format im Verhältnis 4:2:2 kodiert. Das bedeutet, dass ein Makroblock aus 16 x 16 Luminanzwerten und je 8 x 8 Chrominanzwerten besteht.
Intra-Frame-Codierung
Die Intra-Frame-Codierung dient zur Reduktion von räumlichen Redundanzen und ist vom JPEG-Verfahren abgeleitet. Hierbei werden die einzelnen Makroblöcke mit Hilfe der diskreten Cosinus Transformation (DCT) in den Frequenzbereich überführt.
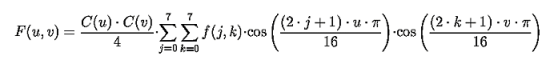
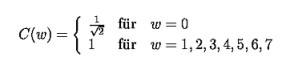

Die Integerfolge 68 0 3 0 0 0 -1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 ... 0 aus dem obigen Bild wird z.B. als (0,68) (1,3) (3,-1) (1,1) (14,2) (0,0) codiert.
Diese Paare können dann mit Hilfe einer Entropiecodierung (z.B. Huffmancodierung) optimal codiert werden.Das obige Beispiel ist jedoch nur für den ersten Block eines Bildes korrekt, denn der Wert der niedrigsten Frequenz, also der (0,0)-Koeffizient (auch DC-Koeffizient genannt), wird - anders als die restlichen Werte - als Differenz zum DC-Koeffizienten des vorherigen Blockes codiert. Diese Art der Codierung (Differential Pulse Code Modulation - DPCM) wird benutzt, da aufeinander folgende DC-Koeffizienten häufig einen ähnlichen Wert haben und somit die benötigte Bitzahl gut verringert werden kann.
Inter-Frame-Codierung
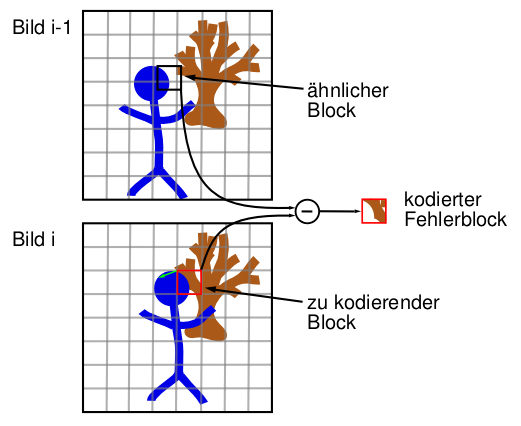
In einer Videosequenz sind sich aufeinander folgende Bilder häufig sehr ähnlich. Diese Ähnlichkeiten werden bei der Inter-Frame-Codierung ausgenutzt, um eine weitere Kompression zu erhalten. Hierbei wird für einen Makroblock des zu codierenden Bildes in einem vorherigen Bild (in gewissen Grenzen) nach einer möglichst großen Ähnlichkeit gesucht. Wird solch eine Übereinstimmung gefunden, so wird nicht der Makroblock, sondern ein Bewegungsvektor, der die Verschiebung bzgl. des gefundenen Blocks des vorherigen Bildes angibt sowie der dadurch entstehende Fehler codiert. Wird keine Übereinstimmung gefunden, so wird der Makroblock mit Hilfe der Intra-Frame-Codierung codiert.
Bildtypen
Innerhalb einer codierten Videosequenz existieren bis zu drei verschiedene Bildtypen, die sich in der Art ihrer Codierung unterscheiden. I-Frames enthalten keine Bewegungskompression und wurden ausschließlich mit Hilfe der Intra-Frame-Codierung erzeugt. P- und B-Frames wurden mittels Inter-Frame-Codierung erstellt, wobei P-Frames nur Bewegungsvektoren bzgl. früherer Frames enthalten und B-Frames auch Vektoren enthalten, die auf zukünftige Bilder verweisen. Die Bewegungsvektoren von P- und B-Frames dürfen sich jedoch nicht auf beliebige vorherige oder zukünftige Frames beziehen, sondern immer nur auf den nächsten I- oder P-Frame. B-Frames sind bei den hier betrachteten Formaten nur in H.263, MPEG-1 und MPEG-2 zu finden. Bei H.261 kommt lediglich die unidirektionale Bewegungskompression der P-Frames zum Einsatz.
Bildreihenfolge
Der erste Frame einer Sequenz ist immer ein I-Frame, darauf folgen einige P- und (außer bei H.261) B-Frames und anschließend wieder ein I-Frame. Die Bewegungskompression beschränkt sich meist auf eine kleine Gruppe von Bildern, damit sich der Qualitätsverlust nicht zu weit fortpflanzen kann.
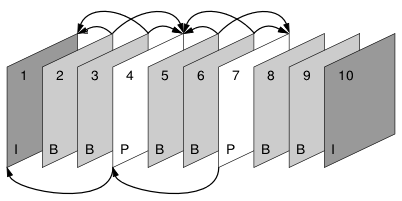
Aufgrund der bidirektionalen Bewegungskompression bei B-Frames ist es bei der Decodierung von H.263, MPEG-1 und MPEG-2 notwendig, die Reihenfolge zu vertauschen. Es müssen also zunächst alle I- und P-Frames, auf die sich die B-Frames beziehen, decodiert werden. Im obigen Beispiel bedeutet dies, dass die Frames in der Reihenfolge 1, 4, 2, 3, 7, 5, 6, 10, 8, 9 übertragen und auch decodiert werden.
Detailliertere Informationen zu den einzelnen Formaten sind auf den Internetseiten unter Links zu finden