Seminar Hochleistungskommunikation
Leistungsverhalten von TCP über ATM
Nick Seggelke
TU Braunschweig
Wintersemester 1997/98
Kapitel 1
Einleitung
Die TCP/IP-Protokollfamilie wurde Ende der siebziger Jahre entwickelt. Das TCP-Protokoll als solches wurde 1981 im RFC 793 (vgl. [6]) dokumentiert. Es war ursprünglich als Transportprotokoll für Weitverkehrsnetze mit Geschwindigkeiten bis zu 56 kbit/s und langen Verzögerungszeiten konzipiert worden. Ziel war es, in Verbindung mit IP als verbindungslosem Best-Effort-Dienst auf der Netzebene einen zuverlässigen und auch fehlerkorrigierenden verbindungsorientierten Transportdienst bereitzustellen.
Erstmals mit der Freigabe des BSD-Unix 4.2 in die Public Domain im Jahre 1983 wurde auch das TCP/IP-Protokoll mitverteilt. Dies führte in der Folge zu einem breiten Einsatz von TCP/IP und entsprechender Anwendungen auch im LAN-Bereich.
Seit 1987 haben sich einige Entwickler Gedanken über mögliche Beschränkungen von TCP beim Einsatz in Hochgeschwindigkeitsnetzen gemacht. Diese Diskussion wurde u.a. von Greg Chesson ausgelöst, der 1987 auf einer Konferenz die Auffassung vertrat, daß TCP/IP niemals höhere Transferraten als 10 Mbit/s zulassen würden.
Heute werden die TCP/IP-Protokolle aber sowohl in Hochgeschwindigkeitsnetzen im allgemeinen als auch in ATM-Netzen im speziellen eingesetzt. Hierbei sind jedoch einige Prinzipien zu beachten, die Gegenstand dieser Ausarbeitung sind.
Kapitel 2 dieser Ausarbeitung beschäftigt sich mit den grundlegenden Prinzipien von TCP, die sowohl für LAN's auf Ethernetbasis als auch für ATM-LAN's gelten. Dabei wird besonders auf solche Aspekte eingegangen, die speziell in Hochgeschwindigkeitsnetzen Probleme verursachen.
Kapitel 3 geht dann genauer auf den Einsatz von TCP in ATM-Netzen ein und setzt sich mit den dabei auftretenden Problemen auseinander. Speziell werden hier die Ursachen für Zellverluste in ATM-Netzen aufgegriffen und mögliche Lösungsansätze vorgestellt
Kapitel 2
Prinzipien von TCP
Dieses Kapitel befasst sich mit grundlegenden Prinzipien von TCP, die sowohl in herkömmlichen Netzen z.B. auf Ethernet-Basis als auch in Hochgeschwindigkeitsnetzen gelten. Insbesondere die Abschnitte Flußkontrolle und Staukontrolle beschäftigen sich mit Apsekten, die in ATM-Netzen Probleme verursachen.
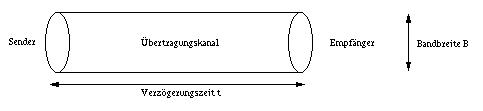
Vereinfacht wird hier ein Übertragungssystem angenommen, das aus einem Sender, einem Empfänger und einem Übertragungskanal besteht.
Der Übertragungskanal besitzt eine Breite B und eine Verzögerungszeit t. Das Produkt aus B und t gibt dann die Anzahl der Daten an, die sich maximal auf dem Weg zwischen Sender und Empfänger befinden können. Um eine hohe Transferrate zu erzielen, muß man während der Dauer des Transfers einen hohen Datenstrom zwischen Sender und Empfänger aufrecht erhalten, d.h. eine Datenmenge B*t im Transit halten.
Hat der Empfänger Einfluß auf das Verhalten des Senders während des Datentransfers, so spricht man vom Closed Loop Flow Control, im anderen Fall vom Open Loop Flow Control. TCP arbeitet im erstgenannten Modus. Der Empfänger hat die Möglichkeit, die Transferrate des Senders abzubremsen oder ein Weitersenden zu veranlassen. Das bedingt allerdings, daß der Datenstrom zwischen Sender und Empfänger B*2t sein sollte (Rückkopplungsschleife muß einbezogen werden), wenn der Übertragungskanal maximal ausgelastet sein soll.
2.2 Grundbegriffe zu Sender und Empfänger
Die Abbildung des Schichmodells verdeutlicht einige Grundbegriffe im TCP-Protokoll. 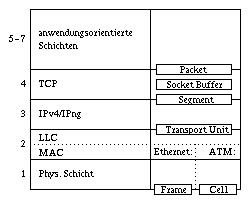
Es bedeuten dabei:
TCP ist ein verbindungsorientiertes Protokoll und hat die Aufgabe, den darüberliegenden Anwendungen (z.B. FTP oder Telnet) einen gesicherten Datentransfer zu bieten, der auch in Fehlersituationen die Korrektheit und Reihenfolge der Daten sichert. TCP bedient sich dazu des unzuverlässigen IP-Protokolls, das weder die Ablieferung der Daten beim Empfänger (Paketverlust) noch den Erhalt der Reihenfolge (Vertauschung durch unterschiedliche Wegewahl) garantiert. Diese Aufgabe muß also von TCP übernommen werden.
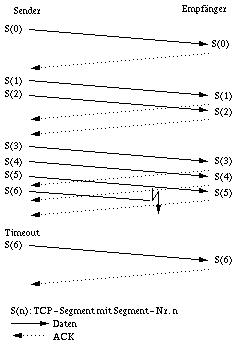
Wesentliches Element im TCP ist ein Fenstermechanismus mit positivem Quittungsverfahren. Positiv bedeutet, daß der Empfänger dem Sender eine Quittung (ACK) sendet, wenn er ein Datenpaket korrekt empfangen hat. Ein ausbleibendes ACK zeigt dem Sender dann den Verlust von Daten an.
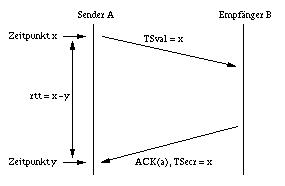
Der Sender bildet dynamisch die sogenannte roundtrip time (rtt). Das ist die Zeit, die zwischen dem Aussenden eines Datenpakets und dem Empfang der zugehörigen Quittung vergeht. Aus der rtt wird die retransmission time gebildet: retransmission time = 2*rtt . Bleibt ein ACK innerhalb der retransmission time aus, wird die Datenübertragung auf Senderseite ab dem letzten noch nicht quittierten Datensegment wiederholt.
Ein ausbleibendes ACK zeigt nur an, daß ein Paket verloren gegangen ist, nicht aber die Ursache des Verlustes. So ist es möglich, daß ein Datensegment tatsächlich im Netz verloren wurde, andererseits ist es aber auch möglich, daß sich ein vorübergehender Stau im Netz aufgebaut hat und die Auslieferung des Datensegments über die retransmission time hinaus verzögert. In jedem Fall startet der Sender aber mit der Wiederholung, so daß der Datenverkehr im Netz u.U. erheblich erhöht wird und so vorhandene Staus weiter verstärkt werden. Und dies umso mehr, je größer das Fenster ist. Um dieses Problem zu mildern wurde das sogenannte Slow Start-Verfahren eingeführt (siehe Abschnitt Staukontrolle)
Die Größe eines Fensterinhalts ist die maximale Datenmenge, die der Sender bei diesem Verfahren ins Netz schicken darf. Dies bedeutet, daß die Kompenenten des Netzes auf dem Weg vom Sender zum Empfänger in der Lage sein müssen, die Datenmenge zu puffern, wenn Datenverluste vermieden werden sollen (u.U. für alle simultan bestehenden TCP-Verbindungen).
TCP verwendet zur Staukontrolle das Slow Start-Verfahren. Der Sender startet mit dem Transfer des ersten Datensegments und wartet dann auf die zugehörige Quittung. Nach Erhalt dieser Quittung werden vom Sender zwei Segmente ins Netz geschickt und er wartet wiederum auf die zugehörigen Quittungen. Danach werden vier Segmente gesendet usw. Diese Verdopplung des Congestion Windows wird solange fortgesetzt, bis eine Quittung ausbleibt oder aber die Window Size erreicht ist.
Bleibt eine Quittung aus (d.h. Daten sind verloren gegangen), wird das erreichte Congestion Window gespeichert und das Verfahren wiederholt. In dieser zweiten Phasen wird wieder bei einer Fenstergröße von eins begonnen, die Verdopplung allerdings nur bis zur Hälfte des vorher ermittelten Congestion Windows fortgesetzt. Ist dieser Wert erreicht, wird das Fenster nur noch linear vergrößert. Der Sender tastet sich also langsam an die Fenstergröße heran, bei der vorher ein Datenverlust aufgetreten ist.
2.5 Zeitabläufe
Bleibt eine Quittung aus, müssen zwei Zeitintervalle betrachtet werden:
Im Mittel wird auf den Ablauf der rtt erst nach ca. 250ms reagiert. H.T. Kung und R. Morris stellen in [3] ein minimales Timeout von 1sec für TCP im Falle des Retransmit fest.
|
Nächstes Kapitel |
Kapitel 3
TCP in ATM-Netzen
C. Partridge kommt in [5] zu dem Ergebnis, daß TCP durchaus für einen Datentransfer im Gbit-Bereich geeignet ist. Als Beweis hierfür führt er an, daß mit einem Cray-Supercomputer 790Mbit/s mit der Standard TCP-Implementierung gemessen wurden. Das Problem sei dabei weniger das Erreichen dieser hohen Sende- und Empfangsgeschwindigkeiten als vielmehr das Management der entstehenden Datenmengen on the fly, damit Datenverluste und Transferpausen vermieden werden.
Dieses Kapitel beschäftigt sich mit dem Einsatz von TCP in ATM-Netzen. Dabei wird aber nicht das Augenmerk auf den prinzipiellen Einsatz des TCP-Protokolls gelegt, sondern vielmehr werden die Probleme behandelt, die in ATM-Netzen beim Einsatz von TCP auftreten. Hierzu werden auch mögliche Lösungsansätze präsentiert.
Wie schon in Abschnitt Übertragungsystem beschrieben, sollte die Fenstergröße dem Produkt der Bandbreite B und dem Doppelten der Verzögerungszeit t entsprechen. Dies ist umso wichtiger, wenn eine gute Auslastung bei TCP erreicht werden soll. Diese Produkt wird auch als Latency-Bandwidth-Product bezeichnet.
Herkömmliche TCP-Implementierungen verwenden typischerweise 64kByte als maximale Fenstergröße. Betrachtet man ein lokales Netz mit 1Gbit/s Transferrate und einer Verzögerungszeit von 4ms zwischen Sender und Empfänger, so ergibt sich eine erforderliche Fenstergröße von mehr als 1MByte:
B=1Gbit/s=131.072kByte/s
t=4ms=0,004s
B*2t=131.072kByte/s*0,008s=1.048kByte>1MByte
Der RFC 1323 (vgl. [4]) sieht unter anderem Erweiterungen zur Verwendung größerer Fenstergrößen bis zu 4GByte vor.
Das Problem ist aber weniger die Definition eines größeren Fenster als vielmehr die Datenmenge, die sich auf dem Weg zum Empfänger befindet. Es entsteht immer ein Nachlauf an Daten, wenn der Empfänger die Datenübertragung des Senders stoppt. Das macht eine Staukontrolle sehr problematisch, da der Sender unter Umständen erhebliche Datemengen stauverstärkend in das Netz geschickt haben kann, bevor er gestoppt wird. Gegebenenfalls kann der Stau auch schon wieder beseitigt sein, wenn der Sender reagiert.
Verschiedene Untersuchungen von TCP über ATM haben ergeben, daß sich eine Erhöhung der Window Size positiv auf den Datendurchsatz verhält, solange keine Flußkontrollprobleme durch unangepaßte Transferraten zwischen Sender und Empfänger auftreten.
Als Beispiel sei hier die Konfiguration aus [2] genannt. Dort wurden zwei DEC 3000 AXP mit einem 155Mbit/s-Link auf eine Entfernung von 600km verbunden. Das prinzipielle Ergebnis geht aus der folgenden Abbildung hervor.
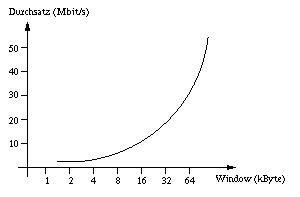
Reduziert man in dieser Konfiguration die Anschlußrate des Zielsystems auf 100Mbit/s, läßt das Sendesystem aber bei 155Mbit/s, so reduziert sich der Durchsatz auf 0,87Mbit/s. Schuld an diesem Verhalten ist die TCP-Flußkontrolle. Näheres dazu in Abschnitt Zellverluste bei TCP über ATM.
In der zweiten Phase des Slow-Start-Verfahrens wird die Fenstergröße nur noch linear vergrößert. Unter der Annahme, daß im obigen Beispiel (LAN mit 1Gbit/s Transferrate bei 4ms Verzögerungszeit) das exponentielle Wachsen des TCP-Fensters schon sehr früh unterbrochen wurde, wächst das Fenster nur noch linear. Bei einer MTU-Size von z.B. 1kByte bedeutet das, daß ungefähr 1.000 roundtrips von jeweils 8ms notwendig sind, bis die Fenstergröße von 1MByte erreicht ist. Das entspricht 8s oder einer "verschenkten" Datenmenge von 1GByte, die während dieser Zeit hätten übertragen werden können.
Auf IP-Ebene wird der Inhalt eines TCP-Fensters als Folge von IP-Datagrammen übertragen. Die Größe eines solchen Datagramms wird durch die Maximum Transfer Unit (MTU) bestimmt. Das Verhältnis von Durchsatz zu MTU Size zeigt in paketorientierten Netzen prinzipiell den gleichen Verlauf wie das Verhältnis von Durchsatz zu Fenstergröße. Daher ist es natürlich wünschenswert, mit großen MTU Sizes zu arbeiten, um den Durchsatz zu erhöhen.
Doch verwenden heute viele TCP-Implementierungen eine veraltete Praxis:
Liegt der Empfänger, zu dem IP-Datagramme übermittelt werden sollen, in einem anderen IP-Subnetz als der Sender, so wird die MTU Size automatisch auf 576Byte verringert. Das kann natürlich erhebliche Durchsatzeinbußen zur Folge haben. Ein Beispiel: Im Regionalen Testbed Nord (RTB Nord), eine Initiative des DFN-Vereins, brechen auf 34Mbit/s-Links zwischen Hamburg und Hannover die Durchsatzraten auf 8-12Mbit/s ein.
Im RCF 1191 wurde die Path MTU Discovery definiert. Dieses Verfahren legt fest, wie Sender und Empfänger eine geeignete MTU Size aushandeln, um einerseits einen möglichst hohen Durchsatz zu erzielen, andererseits aber unerwünschte Fragmentierungen auf dem Weg zu vermeiden. Im oben genannten Testfall wurden bei der Verwendung der Path MTU Discovery Durchsatzraten von 25-28Mbit/s erzielt.
Schon ein TCP-Paket mit nur einem Byte an Nutzdaten benötigt zwei ATM-Zellen, um komplett gesendet werden zu können. Insgesamt werden bei dieser Konstellation 61Byte von der TCP/IP-Schicht an die ATM-Schicht weitergegeben: 40Byte TCP-Header, 20Byte IP-Header und 1Byte Nutzdaten. Diese 61Byte müssen in zwei ATM-Zellen aufgeteilt werden, da eine Zelle nur 48Byte an Nutzdaten enthalten kann. Es werden also 106Byte über das ATM-Netz gesendet, von denen 70Byte Overhead sind.
Bleibt eine Quittung des Empfängers beim Sender aus, so muß dieser zunächst den Retransmit Timer ablaufen lassen , bevor er die Sendewiederholung startet. H.T. Kung und R. Morris kommen in [3] zu dem in der nächsten Abbildung dargestellten Ergebnis. Bei diesem Versuch waren zwei DEC Alpha 3000/400 mit jeweils 155Mbit/s möglichem Durchsatz, einer MTU Size von 9.180Byte und einer TCP-Fenstergröße von 64kByte konfiguriert. Als Switch wurde ein CreditNet ATM Switch mit einem Puffer von 48kByte eingesetzt.
Zunächst ist der Puffer des Switches mit 48kByte gegenüber 64kByte TCP-Fenster unterdimensioniert. Nach einigen Fensterinhalten, die nach wenigen Millisekunden übertragen sind, gehen Zellen durch den Pufferüberlauf im ATM-Switch verloren. Der Empfänger sendet daraufhin keine Empfangsquittung, so daß der Sender den Retransmit Timer ablaufen läßt und dann neu zu senden beginnt. Ein solcher Zyklus dauert ca. 1,5s. Damit ergibt sich der in der folgenden Abbildung gezeigte Verlauf: Innerhalb jeder Sequenz von ca. 1,5s wird nur wenige Millisekunden gesendet, wodurch der Durchsatz entsprechend niedrig ausfällt.
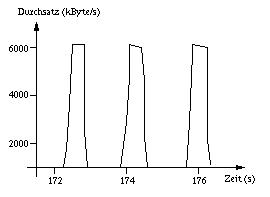
Mit dem Anwachsen der Transferraten in den Datennetzen wurden auch die Zeitabläufe innerhalb des TCP-Protokolls genauer untersucht und entsprechende Verbesserungsvorschläge gemacht. Dazu zählt auch das Fast Retransmit. Hierbei wird auf einen erkannten Paketverlust schon vor Ablauf des Retransmit Timers reagiert. Dieses Verfahren hat aber nur Einfluß auf den Verlust einzelner Pakete.
Nichtsdestotrotz kann mit Fast Retransmit der Durchsatz gegenüber dem herkömmlichen TCP fast verdoppelt werden (vgl. [8]). H.T. Kung und R. Morris weisen in [3] jedoch darauf hin, daß bei einem Pufferengpaß im ATM-Switch typischerweise mehr als nur ein Paket betroffen ist, so daß das Fast Retransmit wirkungslos ist.
3.5 Zellverluste bei TCP über ATM
Die in TCP vorhandene fensterorientierte Flußkontrolle ist für zellorintierte Netze wie ATM kaum geeignet. Treten Zellverluste auf, so laufen relative lange Zeiten bis zum Wiederaufsetzen des Tranfers ab. Dies hat dementsprechende Durchsatzeinbußen zur Folge.
Romanow hat in [7] die in der folgenden Abbildung dargestellte Konfiguration untersucht.
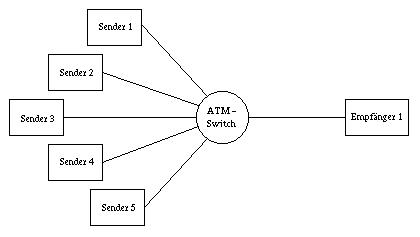
Er ermittelte den TCP Goodput für diese Konfiguration. Der Goodput ist der Durchsatz ohne Retransmissions für eine Window Size von 64kByte und verschiedenen MTU Sizes sowie für verschiedene Puffergrößen im ATM-Switch.
Das Ergebnis ist in der folgenden Abbildung dargestellt.
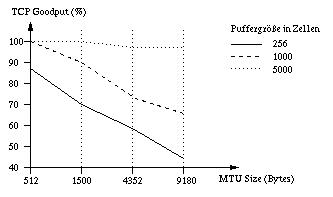
Dort ist eine eindeutige Tendenz abzulesen: Ab einer bestimmten Puffergröße sinkt der Durchsatz mit steigender MTU Size. Romanow hat in [7] den Versuch auch in einem paketorientierten Netz wiederholt. Dort bleibt die Durchsatzrate bei rund 97%.
Die Ursache für die schlechten Werte im zellorientierten Netz liegt hauptsächlich im Puffer des ATM-Switches. Wenn der Pufferbereich im Switch erschöpt ist, treten Zellverluste über alle bestehenden TCP-Verbindungen verteilt auf, da der Switch die Paketstruktur nicht kennt (Welche Zellen gehören zu welchem Paket?), sondern die Zellen nur vermittelt. Das hat zur Folge, daß auf dem Weg zu allen Empfängern viele beschädigte Pakete weitergeleitet werden. Diese völlig nutzlosen Datentransfers belasten aber nur das Netz, was zu einem schlechten TCP Goodput führt. Im Gegensatz dazu werden in paketorientierten Netzen beschädigte Pakete verworfen und belasten das Netz nicht weiter. Der fallende Kurvenverlauf mit steigender MTU Size ist damit zu erklären, daß bei steigender Paketgröße die Wahrscheinlichkeit höher ist, daß ein Paket von einem Zellverlust betroffen ist.
Als weiteren Grund führt Romanow die schlechte Auslastung des Links zum Empfänger an. Da die Zellen der einzelnen TCP-Verbindungen verschachtelt sind, sind nahezu alle TCP-Verbindungen zum gleichen Zeitpunkt von Zellverlusten betroffen. Ein Pufferengpaß betrifft also mehrere TCP-Verbindungen gleichzeitig. Das hat aber auch zur Folge, daß alle Verbindungen nahezu gleichzeitig wieder mit dem Slow Start beginnen. In der Anfangsphase des Slow Starts ist aber die Fenstergröße zu klein, um den Link auslasten zu können. Dadurch sinkt der TCP Goodput wiederum ab.
Je größer die MTU Size ist, desto größer ist auch die Gefahr, daß mehrere TCP-Verbindungen gleichzeitig von Zellverlusten betroffen sind (Verschachtelung der Zellen). Daher sinkt der TCP Goodput mit steigender MTU Size wiederum ab.
In paketorientierten Netzen werden dagegen bei einem Pufferengpaß z.B. in einem Router gezielt Pakete verworfen. Die Wahrscheinlichkeit, daß davon mehrere TCP-Verbindungen gleichzeitig betroffen sind, ist geringer.
Wie oben ausgeführt, ist die Übertragung von nutzlosen Zellen eine Hauptursache für den schlechten Durchsatz von TCP über ATM. Eine Möglichkeit zur Durchsatzsteigerung ist das Verwerfen von Zellen eines Pakets, die einen Switch passieren, wenn von diesem Paket bereits eine Zelle verworfen wurde. Das Vermitteln von nutzlosen Zellen bleibt so aus. Diese Methode ist als Partial Packet Discard bekannt.
Partial Packet Discard kann auf VC-Basis signalisiert werden. Sobald der Switch eine Zelle des VC's verwirft, werden alle weiteren Zellen für diesen VC ebenfalls verworfen, solange bis der AUU-Parameter in einer ATM-Zelle gesetzt ist und das Ende des AAL-Pakets anzeigt. Diese Zelle wird aber nicht verworfen.
Im Switch selbst müssen zusätzliche Informationen für die VC's gehalten werden:
Im Gegensatz zum Partial Packet Discard kann das Early Packet Discard-Verfahren eingesetzt werden, wenn Pufferüberläufe drohen. Auch das Early Packet Discard verwirft ganze Paket und arbeitet ebenfalls auf VC-Basis.
Bei einem drohenden Pufferüberlauf wird die nächste ankommende Zellen eines VC's verworfen, der Early Packet Discard verwendet. Danach werden alle folgenden Zellen dieses VC's ebenfalls verworfen, bis das gesamte AAL5-Paket verworfen wurde. Dazu kann wieder der AUU-Parameter des ATM-Headers verwendet werden.
Diese Methode gilt zwar nicht als fair, da unter Umständen nicht diejenigen Zellen verworfen werden, die den Engpaß ausgelöst haben. Auf der anderen Seite gilt Early Packet Discard als wirkungsvoll, so daß schon einige Hersteller (z.B. Fore) dieses Verfahren verwenden.
Um Early Packet Discard realisieren zu können, benötigt man auch hier noch zusätzliche Informationen
Weiterführende Details zu Partial Packet Discard und Early Packet Discard findet man in [1].
|
|
Literaturverzeichnis
[1] A. Romanow, S. Floyd. Dynamics of TCP Traffic over ATM Networks.
[2] B. J. Ewy, J. B. Evans, V. S. Frost, G. J. Minden. TCP/ATM Experiences in the MAGIC Testbed
[3] H. T. Kung, R. Morris. Detailed Behavior of TCP over ATM. 1995.
[4] V. Jacobsen. TCP Extensions for High Performance. RFC 1323. 1995
[5] C. Partridge. Gigabit Networking. Addison Wesley, 1993.
[6] J. Postel. Transmission Control Protocol. RFC 793. 1981.
[7] A. Romanow. TCP over ATM: Some Performance Results. ATM Forum, 1993
[8] S. Keung, S. Kai-Yeung. Degradation in TCP Performance under Cell Loss. ATM Forum Technical Commitee, Traffic Management Sub-working Group, 1994.